# 1. Node 简介
# 1.异步 I/O
# 2.事件与回掉函数
# 3.单线程
单线程的缺点:
- 无法利用多核处理器
- 错误会引起整个应用退出,应用的健壮性值得考验
- 大量计算占用 cpu 导致无法继续调用异步 I/O
# 4.跨平台
- 操作系统与 Node 上层模块系统之间构建了一层平台层架构,即 libuv
- 混合应用
# 5.低资源占用
- 适合做云平台开发
# 6.前端赋能
- serverless
- 工具编写
- 桌面图形界面应用程序
# 1.5 Node 应用场景
- I/O 密集型适合 IO 密集型,是因为 js 天生的异步写法,并不是比其他语言优秀,也因为 node 刚出的时候 java 对异步支持不是很好。
- 不擅长 CPU 密集型
- 与一流系统和平共处
- 分布式应用
# 2. 模块机制
在 Node 中引入模块,需要经历如下 3 个步骤:
- 路径分析
- 文件定位
- 编译执行
在 node 中,模块分为两类:
- 核心模块:node 提供的模块。核心模块部分在 node 源代码的编译过程中,编译进了二进制执行文件。在 node 进程启动时,部分核心模块就被直接加载进内存中,所以这部分核心模块引入时,文件定位和编译执行这两个步骤可以省略掉,并且在路径分析中有限判断,所以它的加载速度时最快的。
- 文件模块:用户编写的模块。文件模块时在运行时动态加载,需要完整的路径分析、文件定位、编译执行过程,速度比核心模块慢。还有一种特殊的文件模版叫做
自定义模块,这类模块的查找是最费时的,因为它是沿路径逐级递归查找 node_modules 目录
# 2.2 Node 的模块实现
优先从缓存加载 Node 对引入过的模块都会进行缓存,以减少二次引入时的开销。不同与浏览器的是,Node 缓存的是编译和执行之后的对象。
路径分析
require()方法接受一个标识符作为参数
1.1 模块标识符分类
核心模块,如
http、fs、path.或..开始的相对路径文件模块
以/开始的绝对路径文件模块
非路径形式的文件模块,也就是
自定义模块1.2 文件定位
文件扩展名分析
- 如果没有提供扩展名,则按照
.js、.json、.node补足扩展名,依次尝试
- 如果没有提供扩展名,则按照
目录分析和包 - 在 require 分析文件扩展名之后,可能没有找到对应文件,但是得到了一个目录,这在引入自定义模块和逐个模块路径进行查找时会出现,此时 node 会将目录当作一个包来处理 - 然后 node 对当前目录的 package.json 文件进行
JSON.parse()解析,取出main的值对文件进行定位,如果缺少扩展名,则进入扩展名分析步骤 - 如果main属性指定的文件名错误,或者没有package.json文件,node会将index当作默认文件名,然后依次查找index.js、index.json、index.node- 如果目录分析过程没有找到任何文件,则进入下一个模块路径进行查找。如果模块路径数组都没有查到,则抛出失败的异常。 1.3 模块编译
在 node 中,每个文件模块都是一个对象,它的定义如下:
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
if (parent && parent.children) {
parent.children.push(this);
}
this.filename = null;
this.loaded = false;
this.children = [];
}
编译和执行是引入文件模块的最后一个阶段。定位到具体的文件后,Node 会新建一个模块对象,然后根据路径载入并编译。不同的扩展名,编译方式不同:
.js,通过fs模块同步读取文件后编译执行。.node,这是用c/c++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件。.json,通过fs模块同步读取后,用JSON.parse()解析返回结果.- 其他格式文件,都按照
.js文件载入。
每一个编译成功的模块都会将其文件路径作为索引缓存在require.cache对象上,以提高二次引入的性能
如果想对其他格式文件加载,可以通过扩展require.extensions['.ext']的方式实现。
但是从v0.10.6开始,官方不鼓励通过这种方式来进行加载,而是希望先将其他语言转换成 js 文件再加载,这样做的好处在于不将繁琐的编译加载等过程引入 Node 的执行过程中
- JS 模块的编译在
commonjs规范中,我们知道每个模块存在require、exports、module三个变量,但是在模块文件中并没有被定义,为了防止污染全局变量,在编译的过程中,node 对获取的 js 文件内容进行了头尾包装,头部添加(function (exports, require, module, __filename, __dirname) {\n,尾部添加了\n});,一个正常的 js 文件会被包装成如下的样子:
(function (exports, require, module, __filename, __dirname) {
var math = require("math");
exports.area = function (radius) {
return Math.PI * radius * radius;
};
});
这样每个模块之间都进行了作用域隔离。包装之后的代码会被 vm 原声模块的runInThisContext()方法执行,返回一个具体的function对象,最后,将当前模块对象的exports属性、require方法、module(模块对象自身),以及在文件定位中得到的完整路径和文件目录作为参数传递给这个function()执行。 1.1 exports 和 module.exports
因为 exports 是通过形参的方式传入的,直接赋值形参会改变形参的引用,但并不能改变作用域外的值,比如:
var change = function (a) {
a = 100;
console.log(a); // => 100
};
var a = 10;
change(a);
console.log(a); // => 10
如果要达到 require 引入一个类的效果,请赋值给 module.exports 对象。这个迂回的方案不改变形参的引用。
- C/C++模块的编译 .node 的模块不需要编译,只有加载和执行的过程,在执行的过程中,模块的 exports 对象与.node 模块产生联系,然后返回给调用者。
- JSON 的文件的编译 node 利用 fs 模块读取 json 文件的内容之后,调用 JSON.parse 方法得到对象,然后将它赋给模块对象
exports,以供外部使用
# 2.3 核心模块
核心模块分为 c/c++和 js 编写的两部分,c/c++文件存放在 Node 项目下的 src 目录,javascript 文件存放在 lib 目录下。
- js 核心模块的编译过程
在编译所有 C/C++文件之前,编译程序需要将所有的 js 模块文件编译为 C/C++代码。 1. 转存为 C/C++代码 Node 采用了 V8 附带的 js2c.py 工具,将所有内置的 js 代码(src/node.js 和 lib/*.js)转换成 C++里的数组,生成 C++里的数组,生成 node_natives.h 头文件:
namespace node {
const char node_native[] = { 47, 47, ..};
const char dgram_native[] = { 47, 47, ..};
const char console_native[] = { 47, 47, ..}; const char buffer_native[] = { 47, 47, ..}; const char querystring_native[] = { 47, 47, ..}; const char punycode_native[] = { 47, 42, ..};
...
struct _native { const char* name; const char* source; size_t source_len;
};
static const struct _native natives[] = {
{ "node", node_native, sizeof(node_native)-1 },
{ "dgram", dgram_native, sizeof(dgram_native)-1 }, ...
};
}
在这个过程中,js 代码以字符串形式储存在 node 命名空间中,是不可直接执行的。启动 node 进程时,js 代码直接加载到内存中。
# 2.6 包与 NPM
CommonJS 的包规范由两部分组成:
- 包结构:用于组织包中的各种文件
- 包描述:描述包的相关信息,以供外部读取分析
- 包结构
包实际上是一个存档文件,即一个格式为.zip或tar.gz的文件。安装后解压还原为目录。完整的 CommonJS 规范的包目录应该包含以下这些文件:
- package.json:包描述文件
- bin:用于存放可执行二进制文件的目录。
- lib:用于存放
JavaScript代码的目录 - doc:用于存放文档的目录
- test:用于存放但愿测试用力的代码。
- 包描述文件与 npm
包描述文件用于表达非代码相关的讯息,它是一个 JSON 格式的文件——package.json,位于包的根目录下。CommonJS 为 package.json 文件定义了如下一些字段:
- name:包名,由小写字母和数字组成,不允许出现空格,包名必须唯一
- description 包简介
- version 一个语义化的版本号,这在http://semver.org/ (opens new window)上有详细定义。
- keywords 关键词数组,影响 NPM 搜索
- npm 常用功能
# 3. 异步 IO
3.2 安装依赖包执行安装命令后。npm 会在当前目录创建 node_modules,然后在 node_modules 下创建安装的包名文件夹,接着将包解压到这个文件夹下。
- 全局模式安装:将一个包安装为全局可用的可执行命令,根据包描述文件中的 bin 字段配置,将实际脚本链接到与 Node 可执行文件相同的路径下。如果 Node 可执行文件的位置是/usr/local/bin/node,那么模块目录就是/usr/local/lib/node_modules,最后通过软链接的方式将 bin 字段配置的可执行文件链接到 Node 的可之行目录下。
- 从本地安装:本地安装只需为 NPM 指明 package.json 文件所在的位置即可。它可以是一个包含 package.json 的存档文件,也可以是一个 URL 地址,也可以是一个有 package.json 文件的目录位置。例如:
npm i <tarball file>
npm i <tarball url>
npm i <folder>
从非官方源安装:添加
--registry=http://registry.url即可,例如npm install underscore --registry=http://registry.url。如果使用过程中都采用其他源安装,可以执行以下命令指定默认源:npm config set registry http://registry.url3.3 钩子命令 package.json 中 scripts 字段的提出就是让包在安装将活着写在等过程中提供钩子机制,例:
"scripts": {
"preinstall": "preinstall.js",
"install": "install.js",
"uninstall": "uninstall.js",
"test": "test.js"
}
在以上字段中执行npm install <package>时,preinstall 指向的脚本将会加载执行,然后 install 指向的脚本会被执行。在执行npm uninstall <package>时,uninstall 指向的脚本也许会做一些清理工作。 3.4 发布包
- 上传包:
npm publish <folder>,在这个过程中,npm 会将目录打包为一个存档文件,然后上传到官方源仓库中。 - 管理包权限:通常,一个包只有一个人拥有权限进行发布。如果多人进行发布,可以使用
npm owner命令帮助你管理包的所有者:
npm owner ls xxx // 查看包的所有者列表
npm owner add <user> <package name>
npm owner rm <user> <package name>
3.5 分析包不能确认当前目录下能否通过 require()顺利引入想要的包,可以执行 npm ls 分析包。这个命令可以为你分析出当前路径下能狗通过模块路径找到的所有包,并生成依赖树.
# 3.2 异步 I/O 实现现状
- 异步 I/O 与非阻塞 I/O
操作系统内核对于 IO 只有两种方式:阻塞和非阻塞。
阻塞 I/O 的一个特点是调用之后一定要等到系统内核层面完成所有操作后,调用才结束。阻塞 IO 造成 CPU 等待 IO,浪费等待时间。为了提高性能,内核提供了非阻塞 IO。非阻塞 IO 跟阻塞 IO 的区别为调用之后会立即返回。
但非阻塞 IO 也有一些问题,由于完整的的 IO 并没有完成,立即返回的并不是业务层期望的数据,而仅仅是当前调用的状态。为了获取完整的数据,应用程序需要重复调用 IO 操作来确认是否完成,这种重复调用判断操作是否完成的技术叫轮询。
非阻塞带来麻烦却是需要轮询去确认是否完成数据获取,它会让 CPU 处理状态判断,是对 CPU 资源的浪费。
现存的轮询技术有:
- read
- select
- poll
- epoll
- kqueue
- 现实的异步 I/O
之前的方案都不够好吗,这是在场景限定到了单线程的情况下,多线程的方式回事另一番风景。通过让部分现成进行阻塞 I/O 或者非阻塞 I/O 加轮询技术来完成数据获取,让一个现成进行计算处理,通过现成之间的通信将 I/O 得到的数据进行传递,这就轻松实现了异步 I/O(尽管它是模拟的)
# 3.3 Node 的异步 I/O
完成整个异步 I/O 环节的有事件循环、观察者和请求对象等。
- 事件循环
Node 自身的执行模型——事件循环。
在进程启动时,Node 便会创建一个类似于 while(true)的循环,没执行一次循环体的过程我们成为Tick。每个 Tick 的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在关联的回调函数,就执行它们。然后进入下个循环,如果不再有事件处理,就退出进程。
- 观察者
在每个 Tick 的过程中,如何判断是否有事件需要处理呢?这里必须要引入的概念是观察者。
每个事件循环中有一个或者多个观察者,而判断是否有事件要处理的过程就是向这些观察者询问是否有要处理的事件。
在 Node 中,手贱主要来源于网络请求、文件 I/O 等,这些事件对应的观察者有文件 I/O 观察者、网络 I/O 观察者等。观察者将事件进行了分类。
事件循环是一个典型的生产者/消费者模型。异步 I/O、网络请求等则是事件的生产者,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。
在 windows 下,这个循环基于 IOCP 创建,而在*nix 下则基于多线程创建。
# 3.4 非 I/O 的异步 API
Node 中还存在一些与 I/O 无关的异步 API,分别是:setTimeout()、setInterval()、setImmediate()、process.nextTick()
- 定时器调用 setTimeout()或者 setInterval()创建的定时器会被插入到定时器观察者内部的一个红黑树中。每次 Tick 执行时,会从该红黑树中迭代取出定时器对象,检查是否超过定时时间,如果超过就形成一个事件,它的回调函数将立即执行。
- setImmediate() process.nextTick()中的回调函数执行的优先级要高于 setImmediate()。 这里的原因在于事件循环对观察者的检查是有先后顺序的,process.nextTick()属于 idle 观察者, setImmediate()属于 check 观察者。在每一个轮循环检查中,idle 观察者先于 I/O 观察者,I/O 观察者先于 check 观察者。
在行为上,process.nextTick()在每轮循环中会将数组中的回调函数全部执行完,而 setImmediate()在每轮循环中执行链表中的一个回调函数。
# 5. 内存控制
# 5.1.3 v8 的对象分配
通过memoryUsage指令可以查看内存使用情况,heapTotal 和 heapUsed 是 V8 的堆内存使用情况,前者是已申请到的堆内存,后者是当前使用的量
node
> process.memoryUsage()
当我们在代码中声明变量并赋值时,所使用对象的内存就分配在堆中。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,知道堆的大小超过 V8 的限制为止。
为什么 V8 要限制内存使用呢?
以 1.5GB 的垃圾祸首堆内存为例,v8 做一次小的垃圾回收需要 50 毫秒以上,做一次非增量式的垃圾回收甚至要 1 秒以上。这是垃圾回收中引起 js 线程暂停执行的时间,在这样的时间花销下,应用的性能和响应能力都会直线下降。
# 5.1.4 V8 的垃圾回收机制
v8 主要的垃圾回收算法
v8 的垃圾回收策略主要基于分代式垃圾回收机制。内存分为新生代和老生代两代。新生代中的对象为存活时间较短的对象,老生代为存活时间较长嚯常驻内存的对象。
v8 堆的整体大小就是新生代+老生代内存空间。v8 的使用内存没有办法根据使用情况自动扩充。当内存分配过程中超过极限值时,就会引起进程出错。64 位系统下只能使用约 1.4gb 内存。
# 5.1.5 查看垃圾回收日志
启动时添加--trace_gc 参数。
通过在 Node 启动时使用--prof 参数,可以得到 v8 执行时的性能分析数据,其中包含了垃圾回收执行时占用的时间。
# 5.2 高效使用内存
# 5.2.1 作用域
- 变量的主动释放
可以通过 delete 操作来删除引用关系。或者将变量重新赋值,让旧对象脱离引用关系。虽然 delete 操作和冲洗赋值具有相同的效果,但是在 v8 中通过 delete 删除对象的属性有可能干扰 v8 的优化,所以通过赋值方式解除引用更好。
# 5.2.2 闭包
# 5.2.3 小结
无法立即回收的内存有闭包和全局变量引用这两种情况。
# 5.3 内存指标
# 5.3.1 查看内存使用情况
os模块中的totalmem()和freemem()方法可以查看系统内存使用情况,totalmem 是查看系统所有内存,freeemem 是查看闲置内存,以字节为单位。 process.memoryUsage()可以查看 Node 进程的内存占用情况,其中rss是resident set size的缩写,即进程的常驻内存部分,单位是字节。进程的内存总共有几部分,一部分是 rss,其余部分在交换区(swap)或者文件系统(filesystem)中。
# 5.3.2 堆外内存
通过process.memoryUsage()的结果可以看到,堆中的内存用量总是小于进程的常驻内存用量,这意味着 Node 中的内存使用并非都是通过 v8 进行分配的。我们将那些不是通过 v8 分配的内存称为堆外内存。
Buffer对象并非通过 v8 的内存分配机制,所以也不会有堆内存的大小限制。这意味着利用堆外内存可以突破内存限制的问题。
# 5.4 内存泄漏
通常,造成内存泄漏的原因有如下几个:
- 缓存
- 队列消费不及时
- 作用域未释放
# 5.4.1 慎将内存当做缓存
- 缓存限制策略
- 缓存的解决方案进程之间无法共享内存,如果在进程内使用缓存,这些缓存不可避免地有重复,对物理内存的使用是一种浪费。
如果使用大量缓存,比较好的解决方案是采用进程外的缓存,进程自身不储存状态。外部的缓存软件有着良好的缓存过期淘汰策略以及自有的内存管理,不影响 Node 进程的性能,主要可以解决一下两个问题。
- 将缓存转移到外部,减少常驻内存的对象的数量,让垃圾回收更高效。
- 进程之间可以共享缓存。
# 6.1 Buffer 结构
Buffer 是一个像 Array 的对象,但它主要用于操作字节。
# 6.1.1 模块结构
Buffer 是一个典型的 js 与 c++结合的模块,它将性能相关部分用 c++实现,将非性能相关的部分用 js 实现。
Buffer 被放在 Node 全局对象上,无需require()即可直接使用。
# 6.1.2 Buffer 对象
Buffer 对象类似于数组,它的元素为 16 进制的两位数,即 0 ~ 255 的数值。
var str = "深入浅出node.js";
var buf = new Buffer(str, "utf-8");
console.log(buf);
// => <Buffer e6 b7 b1 e5 85 a5 e6 b5 85 e5 87 ba 6e 6f 64 65 2e 6a 73>
上面代码中的中文在 UTF-8 编码下占用 3 个元素,字幕和半角标题点符号占用 1 个元素。
buffer 可以同过 length 得到长度,也可以通过下标访问元素。:
var buf = new Buffer(100);
console.log(buf.length); // => 100
console.log(buf[10]); // 这里会得到一个比较奇怪的结果,它的元素值是一个0~255的随机值
buf[10] = 100;
console.log(buf[10]); // => 100
如果赋值的时候不是 0 ~ 255 之间的整数会怎么样?
- 赋值小于 0,就将该值逐次加 256,直到得到一个 0 ~ 255 之间的整数。
- 赋值大于 255,就逐次减 256,直到得到 0 ~ 255 区间内的数值。
- 赋值是小数,就舍弃小数部分,只保留整数部分。
# 6.1.3 Buffer 内存分配
Node 在内存的使用上应用的是在 C++层面神申请内存、在 js 中分配内存的策略。
为了高效地使用申请来的内存,Node 采用了 slab 分配机制。slab 是一种动态内存管理机制。slab 具有如下 3 种状态。
- full:完全分配状态
- partial:部分分配状态
- empty:没有被分配状态
当我们需要一个 Buffer 对象,可以通过这个方式分配指定大小的 Buffer 对象:new Buffer(size)
Node 以 8kb 为界限来区分 Buffer 是大对象还是小对象:
buffer.poolSize= 8*1024;
这个 8kb 的值也就是每个 slab 的大小值,在 js 层面,以它作为单位单元进行内存的分配。
- 分配小 Buffer 对象
如果指定 Buffer 的大小少于 8kb,Node 会按照小对象的方式进行分配。Buffer 的分配过程中主要使用一个局部变量 pool 作为中间处理对象,处于分配状态的 slab 单元都指向它。创建一个小 buffer 对象会先去检查 pool 对象是否被创建,如果没有被创建,那么创建一个新的 slab 单元指向它。
同时当前 Buffer 对象的 parent 属性指向该 slab,并记录下是从这个 slab 的那个位置(offset)开始使用的,slab 对象自身也记录被使用了多少字节:
this.parent = pool;
this.offset = pool.used;
pool.used += this.length;
if (pool.used & 7) pool.used = (pool.used + 8) & ~7;
当再次创建一个 Buffer 对象时,构造过程中会判断这个 slab 的剩余空间是否足够。如果足够,使用剩余空间,并更新 slab 的分配状态。
如果 slab 剩余的空间不够,将会构造新的 slab,原 slab 中剩余的空间会造成浪费。
由于同一个 slab 可能分配给多个 Buffer 对象使用,只有这些小 Buffer 对象在作用域释放并都可以回收时,slab 的 8kb 空间才会被回收。尽管创建了 1 个字节的 Buffer 对象,但是如果不释放它,实际可能是 8kb 的内存没有释放。
2. 分配大 Buffer 对象如果需要超过 8kb 的 Buffer 对象,将会直接分配一个 SlowBuffer 对象作为 slab 单元,这个 slab 单元将会被这个大 Buffer 对象独占。
// Big buffer, just alloc one
this.parent = new SlowBuffer(this.length); this.offset = 0;
这里的 SlowBuffer 类是在 C++中定义的,虽然引用 buffer 模块可以访问到它,但是不推荐直接操作它,而是用 Buffer 替代。
上面提到的 Buffer 对象都是 js 层面的,能够被 V8 的垃圾回收标记回收。但是其内部的 parent 属性指向的 SlowBuffer 对象却来自与 Node 自身 C++中的定义,是 C++层面上的 Buffer 对象,所用内存不在 V8 的堆中。 3. 小结
简单而言,真正的内存是在 Node 的 C++层面提供的,js 层面知识使用它。当进行小而频繁的 Buffer 奥做时,采用 slab 的机制进行预先申请和事后分配,使得 js 到操作系统之间不必有过多的内存申请方面的系统调用。对于大块的 Buffer 而言,则直接使用 C++层面提供的内存,而无需细腻的分配操作。
# 6.2 Buffer 的转换
Buffer 对象可以与字符串之间相互转换。目前支持的字符串编码类型有如下这几种。
- ASCII
- UTF-8
- UTF-16LE/UCS-2
- Base64
- Binary
- Hex
# 6.2.1 字符串转 Buffer
字符串转 Buffer 对象是通过构造函数完成的:
new Buffer(str,[encoding]);
通过构造函数转换的 buffer 对象,储存的只能是一种编码类型。encoding 参数不传递时,默认按照 UTF-8 编码进行转码和储存。
一个 Buffer 对象可以存储不同编码类型的字符串转码的值,调用 write() 方法可以实现该目的,代码如下:
buf.write(string,[offset],[length],[encoding])
需要小心的是,每种编码所用的字节长度不同,将 Buffer 反转回字符串时需要谨慎处理。
# 6.2.2 Buffer 转字符串
Buffer 对象的 toString()可以将 buffer 对象转换为字符串:
buf.toString([encoding],[start],[end])
# 6.2.3 Buffer 不支持的编码类型
Node 的 Buffer 对象支持的编码类型有限,只有少数的几种编码类型可以在字符串和 buffer 之间转换。为此,Buffer 提供了一个 isEnciding()函数来判断编码是否支持转换:
Buffer.isEncoding(encoding)
将编码类型作为参数传入上面的函数,返回 boolean 值。中国常用的 GBK、GB2312 和 BIG-5 都不再支持的行列中。
对于不支持的编码类型,可以借助 Node 生态圈中的模块完成转换。推荐使用iconv-lite:
var iconv = require("iconv-lite");
// buffer转字符串
var str = iconv.decode(buf, "win1251");
// 字符串转Buffer
var buf = iconv.encode("sample input string", "win1251");
# 6.3 Buffer 的拼接
以下是常见的从输入流中读取内容的事例代码:
var fs = require("fs");
var rs = fs.createReadStream("test.md");
var data = "";
rs.on("data", function (chunk) {
data += chunk;
});
rs.on("end", function () {
console.log(data);
});
其中的 chunk 就是 Buffer 对象,上边的代码有个问题,一旦输入流中有宽字节编码时,问题就会暴露出来。
data += chunk;
这句代码里隐藏了 toString()操作,它等价于:
data = data.toString() + chunk.toString(); // buf.toString()默认使用UTF-8编码
# 6.3.1 乱码是如何产生的
中文字在 UTF-8 下占 3 个字节,当 Buffer 对象的长度没有包含完整的中文时,会被截断,剩下的字节会以乱码形式显示。
# 6.3.2 setEncoding()与 string_decoder()
可读流还有一个设置编码的方法:setEncoding():
readable.setEncoding(encoding)
该方法的作用是让 data 时间中传递的不再是一个 Buffer 对象,而是编码后的字符串。这时输出的中文正确了,只是转码并没有解决宽字节字符被截断的问题,最终乱码问题得意解决,还是在于 decoder 的神奇之处,StringDecoder 在得到编码后,直到宽字节字符串在 UTF-8 编码下是以 3 个字节的方式存储的,所以第一次write()时,只输出前 9 个字节转码形成的字符,“月”字的求安两个字节被保留在 StringDecoder 实例内部。第二次 write()时,会将这两个剩余字节和后续 11 个字节组合在一起,再次用 3 的整数倍字节进行转码。于是乱码问题通过这种中间形式被解决了。
虽然 string_decoder 模块很奇妙,但是它只能处理 UTF-8、Base64 和 UCS-2/UTF-16LE 这 3 中编码。所以还是通过 setEncoding()的方式不可否认能解决大部分的乱码问题,但这并不能从根本上解决该问题。
# 6.3.3 正确拼接 Buffer
剩下的解决方案只有将多个小 Buffer 对象拼接为一个 Buffer 对象,然后通过 iconv-lite 一类的模块来转码这种方式。+=的方式显然不行。正确的拼接方法应该如下边展示的形式:
var chunks = [];
var size = 0;
res.on("data", function (chunk) {
chunks.push(chunk);
size += chunk.length;
});
res.on("end", function () {
var buf = Buffer.concat(chunks, size);
var str = iconv.decode(buf, "utf8");
console.log(str);
});
# 6.4 Buffer与性能
通过预先转换静态内容为Buffer对象,可以有效地减少cput的重复使用,节省服务器资源。在node构建的web应用中,可以选择将页面中的动态内容和静态内容分离,静态内容部分可以通过预先转换为Buffer的方式,使性能得到提升。
文件读取
Buffer的使用除了与字符串的转换有性能损耗外,在文件的读取时,有一个highWaterMark设置对性能的影响至关重要。
fs.createReadStream()的工作方式是在内存中准备一段Buffer,然后在fs.read()读取时逐步从磁盘中将字节复制到Buffer中。完成一次读取时,通过slice()方法去除部分数据作为一个小Buffer对象,再通过data事件传递给调用方。如果Buffer用完,则重新分配一个;如果还有剩余,则继续使用。
每次读取的长度就是用户指定的highWaterMark。
- highWaterMark设置对Buffer内存的分配和使用有一定影响。
- highWaterMark设置过小,可能导致系统调用次数过多。
读取一个相同的大文件时,highWaterMark值的大小与读取速度的关系:该值越大,读取速度越快。
# 7 网络编程
# 7.1 构建TCP服务
TCP服务在网络中十分常见,目前大多数的应用都是基于TCP搭建而成的。
# 7.1.1 TCP
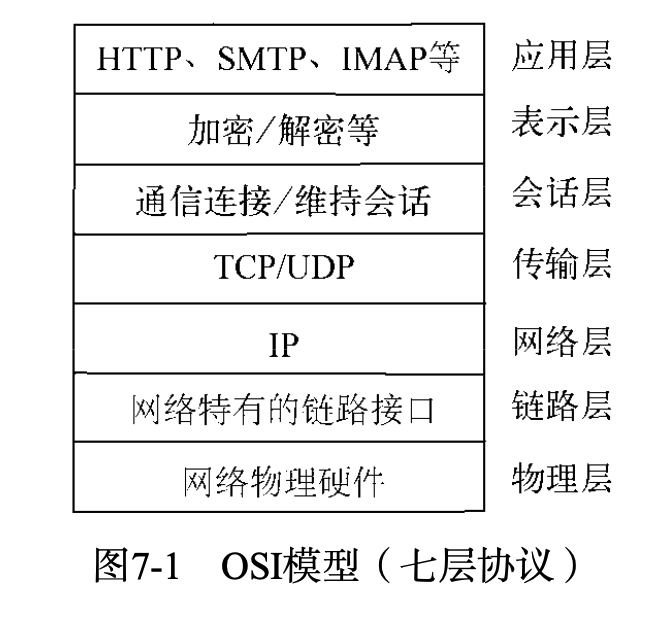
TCP全名为传输控制协议,在OSI模型(由七层组成,分别为物理层、数据链结层、网络层、传输层、会话层、表示层、应用层)中属于传输层协议。许多应用层协议基于TCP构建,典型的是HTTP、SMTP、IMAP等协议。
 TCP是面向连接的协议,其显著的特征是在传输之前需要3次握手形成会话。
TCP是面向连接的协议,其显著的特征是在传输之前需要3次握手形成会话。
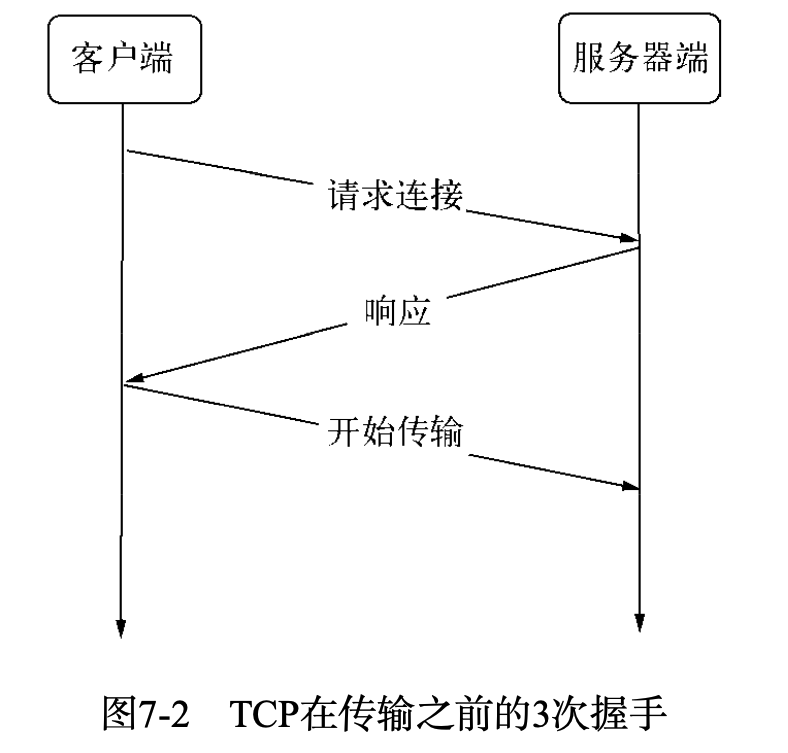 只有会话形成之后,服务器端和客户端之间才能互相发送数据。创建会话的过程中,服务端和客户端分别提供一个套接字,这两个套接字共同形成已给连接。服务器端与客户端则通过套接字实现两者之间连接的操作。
只有会话形成之后,服务器端和客户端之间才能互相发送数据。创建会话的过程中,服务端和客户端分别提供一个套接字,这两个套接字共同形成已给连接。服务器端与客户端则通过套接字实现两者之间连接的操作。
# 7.1.2 创建TCP服务器端
创建服务器:
// serve.js
const net = require("net");
const server = net.createServer((socket) => {
socket.on("data", (data) => {
socket.write("你好");
});
socket.on("end", () => {
console.log("服务端连接断开");
});
socket.on('error',()=>{
console.log('服务异常!!!')
})
socket.write("欢迎光临L.Rain :\n");
});
server.listen(8124, () => {
console.log("server bound");
});
创建客户端访问服务器:
// client.js
var net=require('net');
var client=net.connect({port:8124},()=>{
console.log('client connected');
client.write('world!\r\n');
})
client.on('data',function(data){
console.log(data.toString());
client.end();
})
client.on('end',()=>{
console.log('客户端连接断开')
})
# 7.1.3 TCP服务的事件
- 服务器事件
- listening: 在调用server.listen()绑定端口或者Domain Socket后触发
- connection: 每个客户端套接字连接到服务器端时触发
- close: 当服务器关闭时触发,在调用server.close()后,服务器将停止接收新的套接字连接,但保持当前存在的连接,等待所有连接都断开后,会触发该事件。
- error: 服务器发生异常时触发,如果不设置该事件监听,则服务器将会抛出异常。
- 连接事件